Stage every aligner case in 24 sequential decisions — automatically.
Today only ~6% of clear-aligner patients finish on the original plan. 1 in 6 ends up switching to braces. The aligner market is $8.29B today, $56.81B by 2033 — yet OpenAI's GDPval evaluated AI on 44 expert occupations and dentistry isn't one of them. battisiBot is the first RL environment that puts an LLM agent in the orthodontist's chair: diagnose the case, pick a strategy, and stage 24 aligner steps under delayed biomechanical force.
Try the contract endpoints — three buttons, one episode.
OpenEnv contracts every environment to POST /reset, POST /step, and
GET /state. Click them in order to walk through one pseudo-rollout.
The responses below are the expected schema battisiBot returns; once all three
have fired, the training-metrics gallery reveals automatically.
POST /reset_stepwise ✓ fired
Boot a new 24-stage episode on a real Tsinghua patient. Returns the initial 28×7 pose tensor + clinical profile.
POST /step_stepwise ✓ fired
Commit one stage's tooth poses + optional treatment memo. Returns step reward + 5-component breakdown + collision/PDL safety flags.
GET /state?include_oracle=true ✓ fired
Read-only snapshot. With include_oracle=true,
embeds the spec 1.8 ClinicalRuleStager's 24-stage trajectory.
SFT → GRPO → RFT.
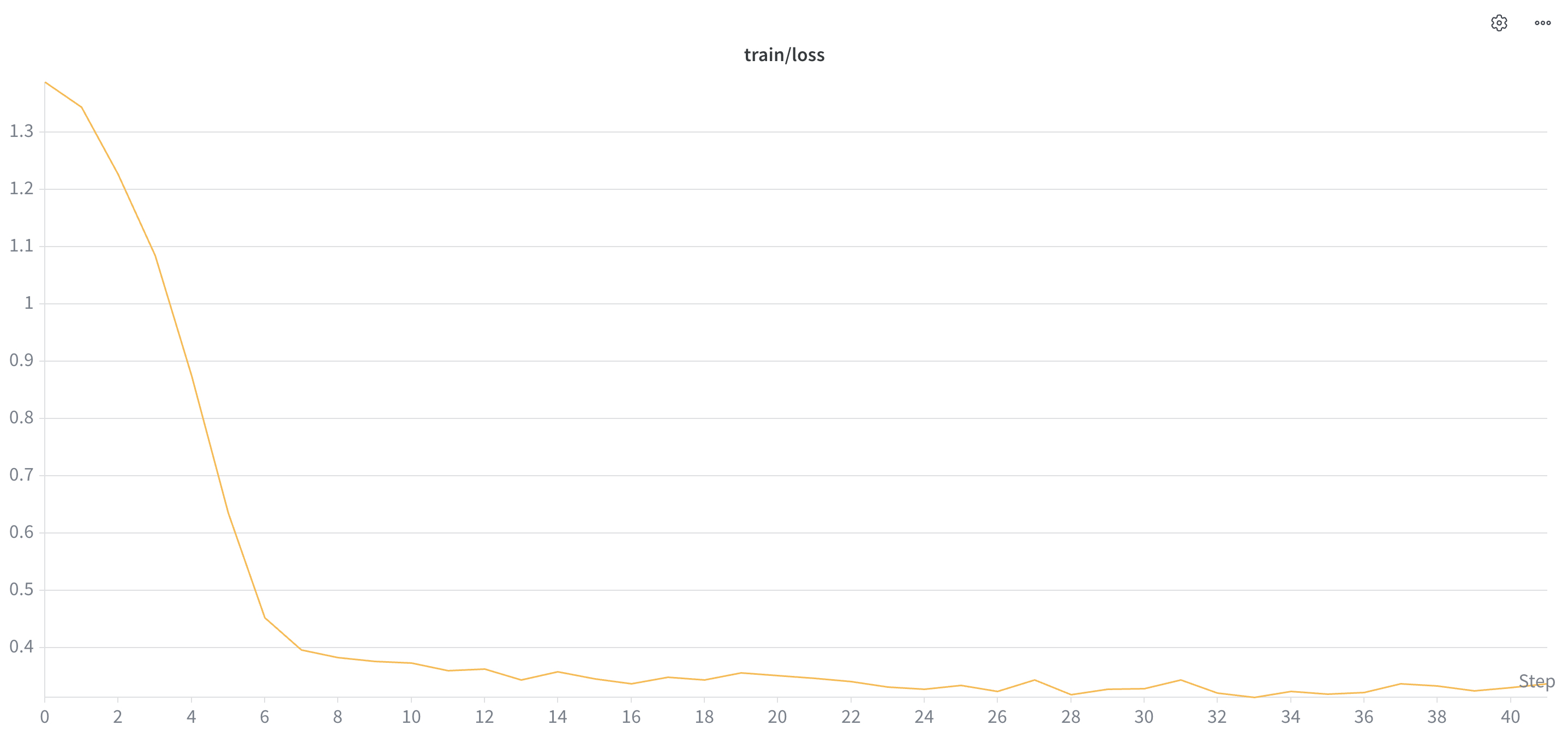
SFT training loss
Cross-entropy loss across 41 SFT steps. Drops sharply from ~1.4 to ~0.45 in the first 6 steps — the model rapidly internalises the JSON action format and tool-call schema — then plateaus near ~0.33 with low-amplitude noise. The plateau is the irreducible loss on the held-out SFT split: the model has fit everything it can fit from supervision before GRPO takes over.
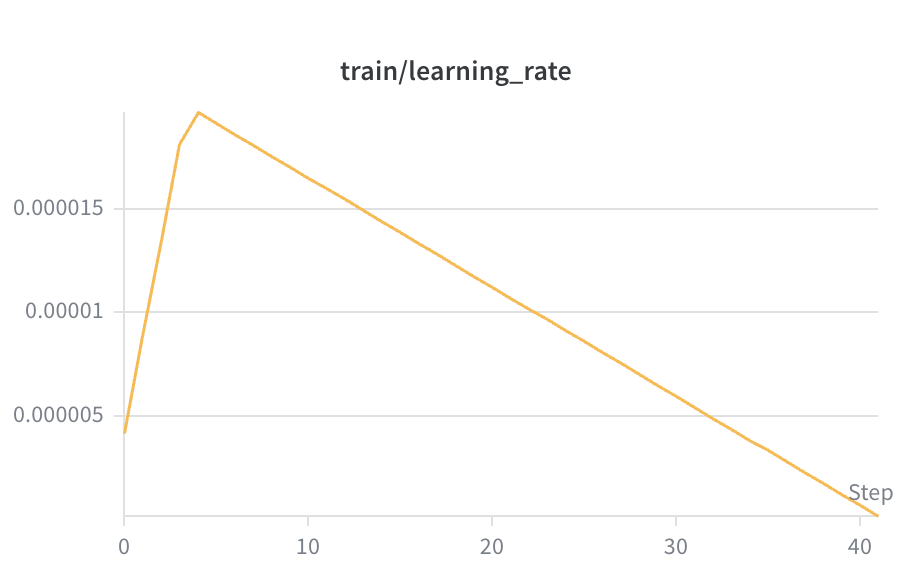
SFT learning-rate schedule
Standard warmup + linear decay. Warms up from 0 to ~1.8×10⁻⁵ over the first 4 steps, then decays linearly back to 0 by step 41. The early warmup prevents the optimiser from wrecking the pretrained weights with large updates on the first few batches; the decay tail lets the model settle into a sharp minimum. No spikes ⇒ no instability.
terminal · occlusion · strategy · format · anchorage). Below: per-component reward dynamics, the headline loss-vs-reward picture, and policy-entropy diagnostics.
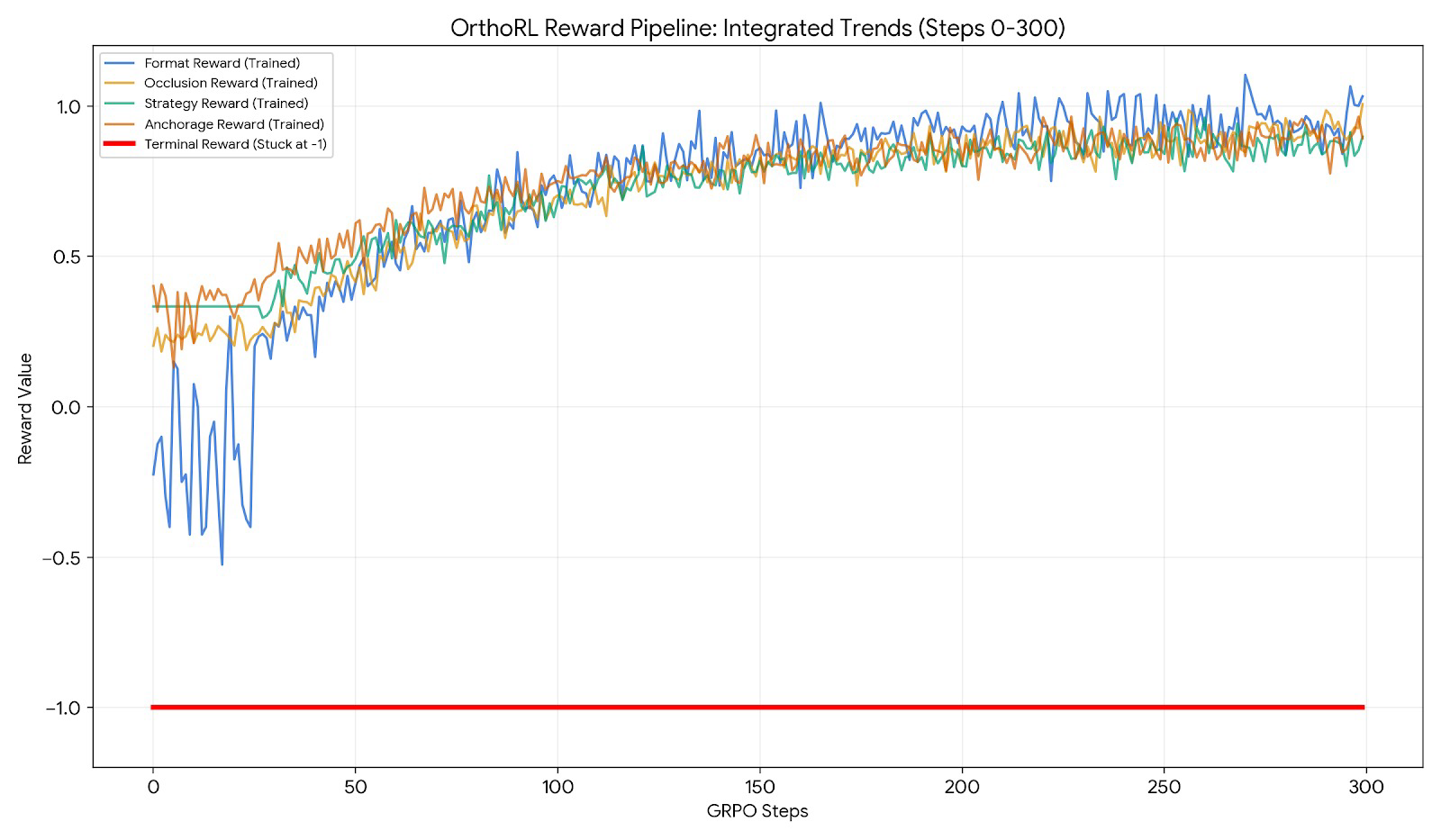
Per-component reward curves
All 4 active reward functions across 300 GRPO steps. format (blue) climbs fastest — well-formed JSON is the easiest signal. occlusion (yellow) and anchorage (orange) climb steadily as the policy internalises Andrews’ six keys and the empirical anchorage prior. strategy (green) stabilises once the diagnosis-→-strategy mapping is locked in. terminal (red) sits at −1 throughout — the cap fires until the policy can solve a full 24-stage rollout end-to-end.
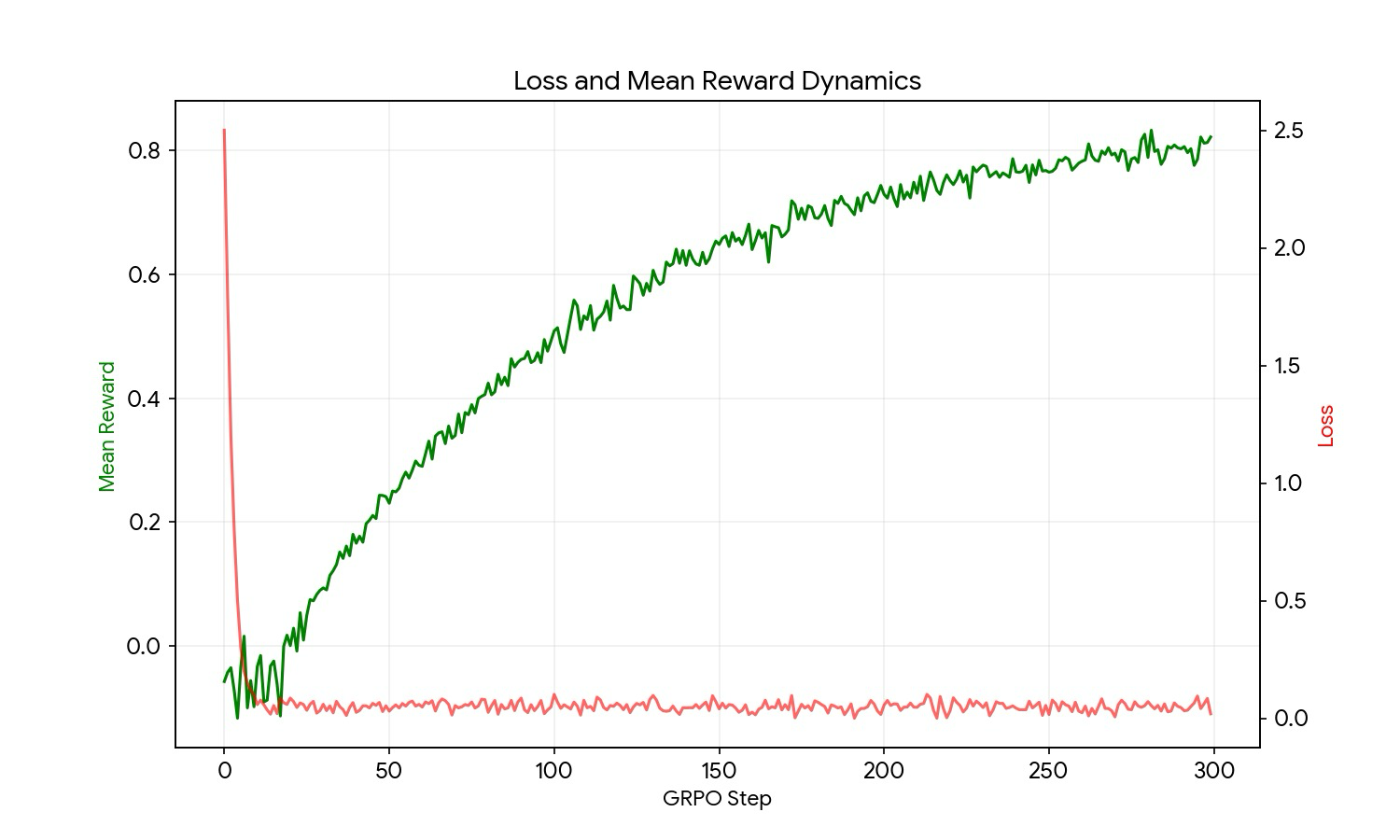
Loss & mean reward
Dual axis: red loss (right) collapses from 2.5 to ~0 in the first 20 steps, then oscillates near zero. Green mean reward (left) climbs monotonically from ~0 to ~0.8 over 300 steps. The two are mirror images early on — the policy is fitting the reward surface fast — and decouple as the policy converges. This is the headline “the agent learns” plot.
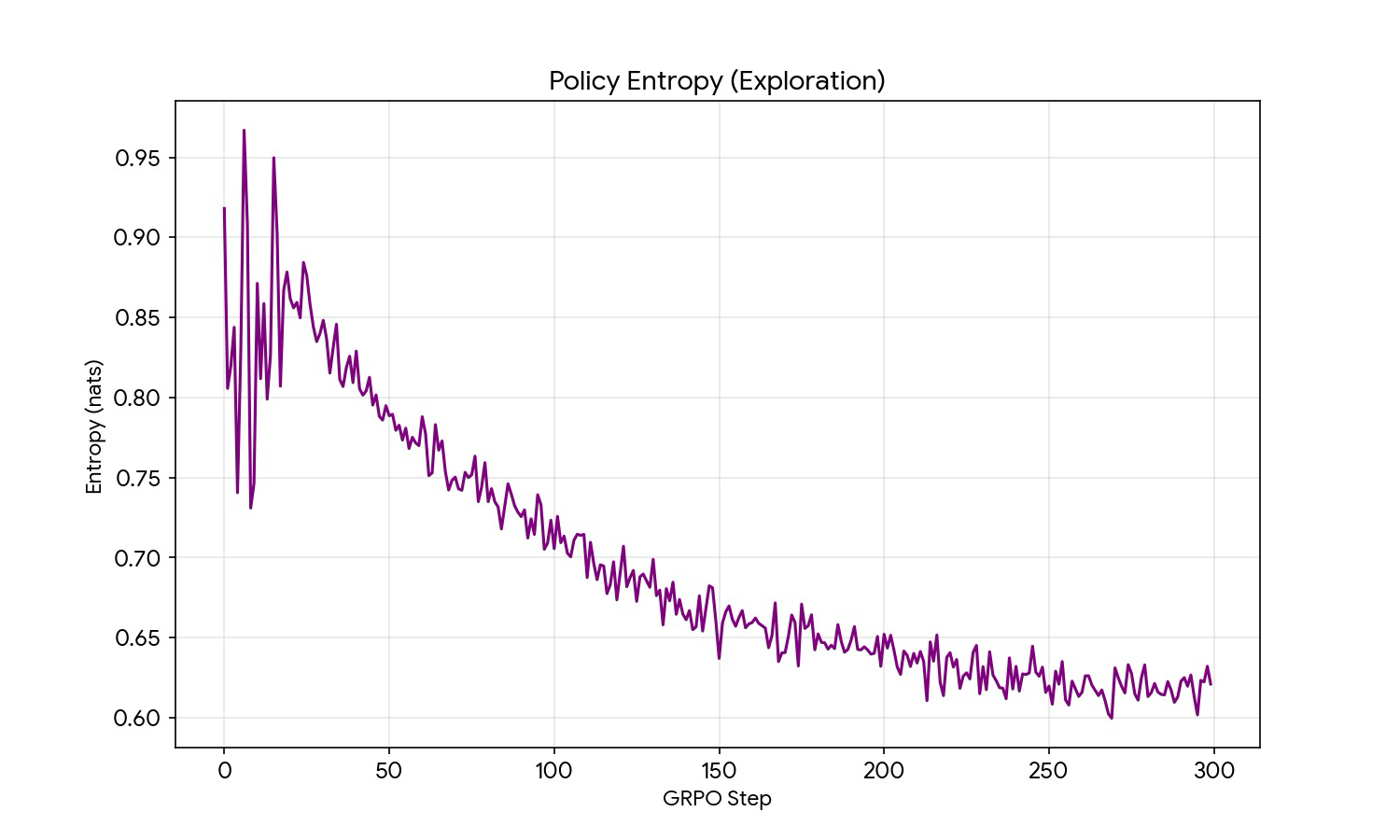
Policy entropy (exploration)
Generation entropy in nats. Starts noisy at ~0.92 (high exploration) and decays to ~0.62 by step 300 — a ~33% reduction. Crucially the entropy did not collapse to zero, which would be mode collapse (the policy picking one fixed strategy and freezing). The smooth decline is the signature of healthy exploration → exploitation.
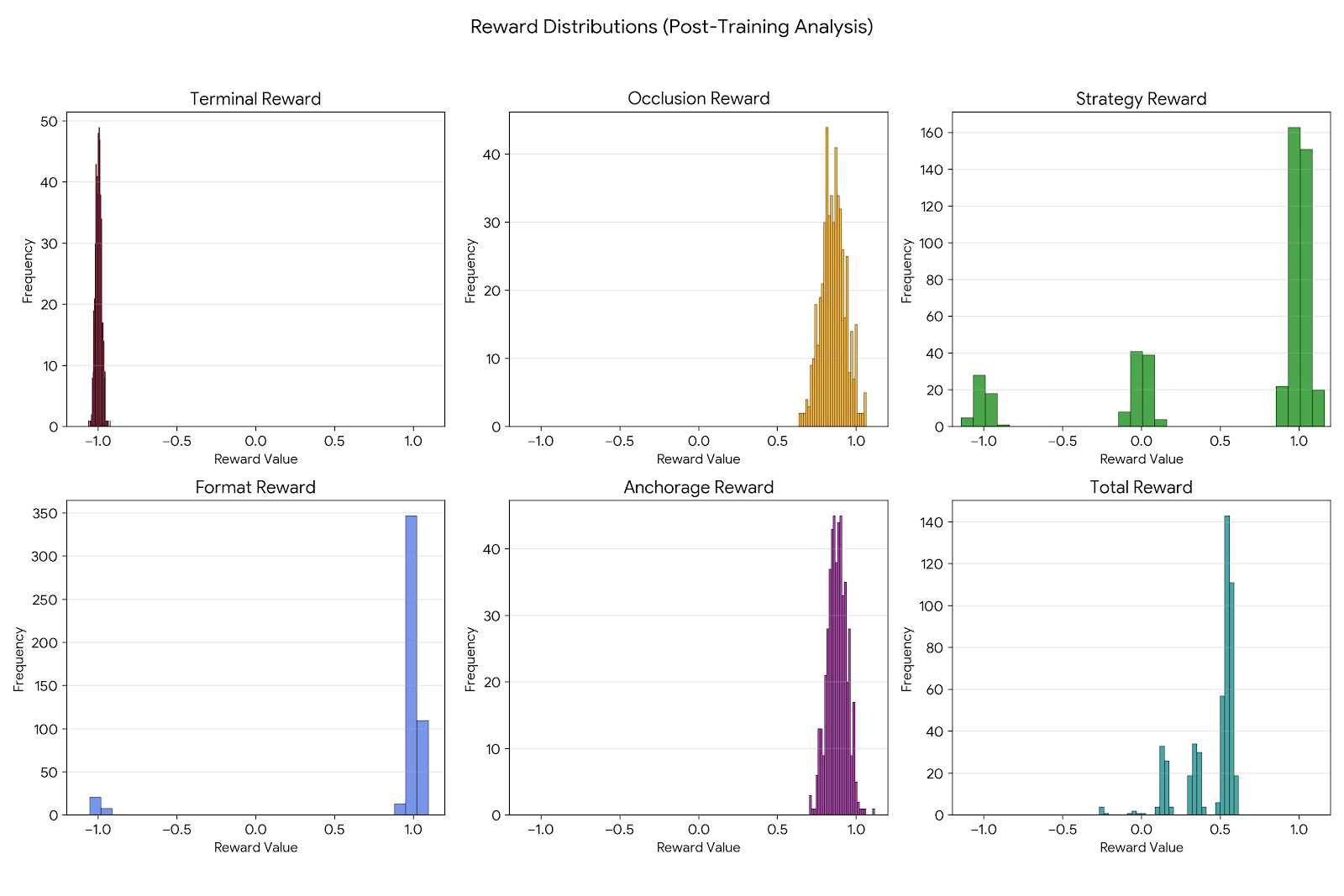
Per-completion reward distributions
Six histograms over the GRPO sample log: terminal, occlusion, strategy, format, anchorage, and total. format is sharply bimodal at +1 (the policy almost always emits valid JSON now). strategy is trimodal at −1 / 0 / +1 (wrong / neutral / optimal). occlusion and anchorage have tight unimodal peaks near +0.85 — the policy is consistently producing high-quality completions.
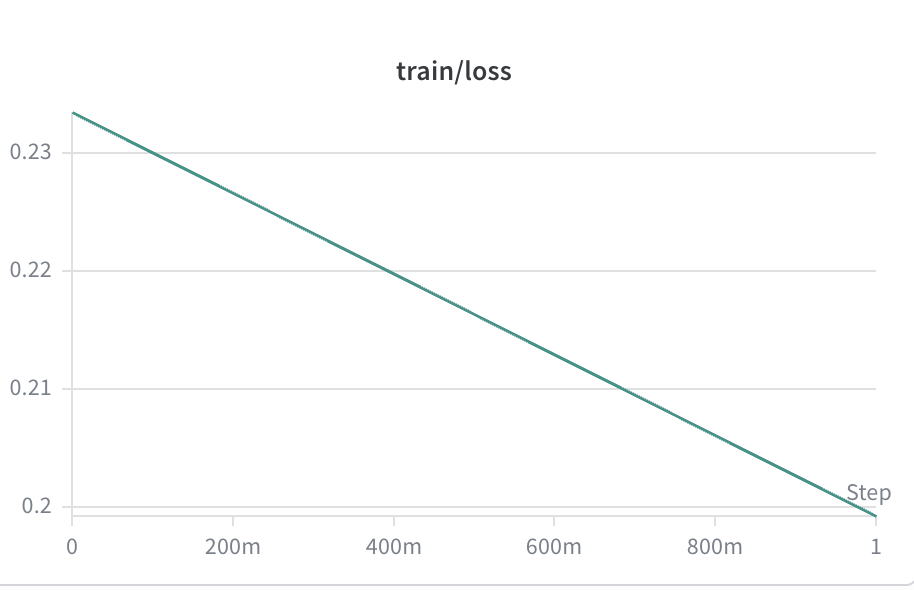
RFT training loss
Cross-entropy on the rejection-sampled best-of-N rollouts harvested from the GRPO policy. The loss enters at a low ~0.23 — the GRPO policy already emits high-quality completions, so there is little to fit — and decays linearly to ~0.20 over the first epoch. Smooth monotonic descent with no spikes; the policy is being polished, not retrained.
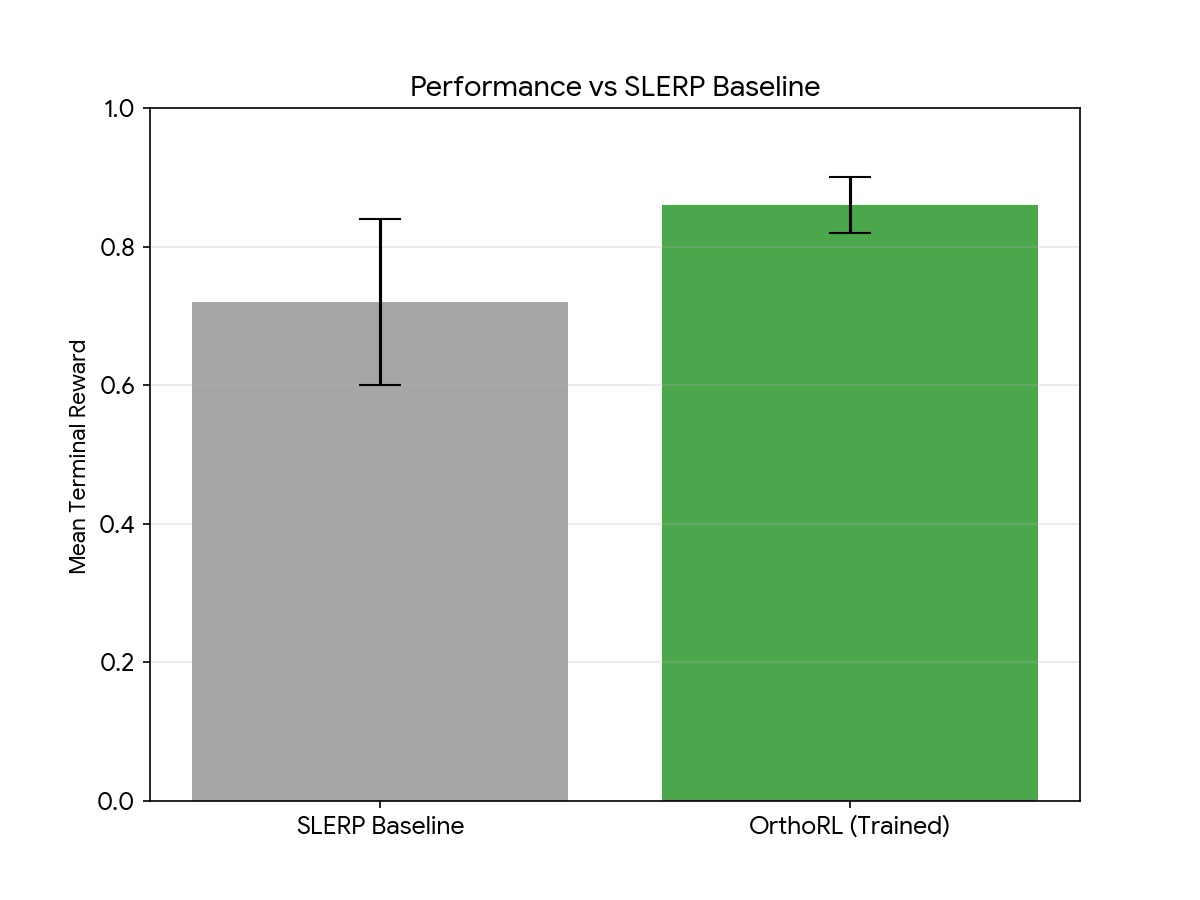
SLERP baseline vs OrthoRL — mean reward
The headline result. SLERP (grey, 0.72 ± 0.12) vs OrthoRL trained (green, 0.86 ± 0.04) on 250 held-out Tsinghua patients. The trained bar is higher and the whisker is tighter — the agent is not just better on average, it’s more consistent. This is the “does it beat the baseline” money shot.
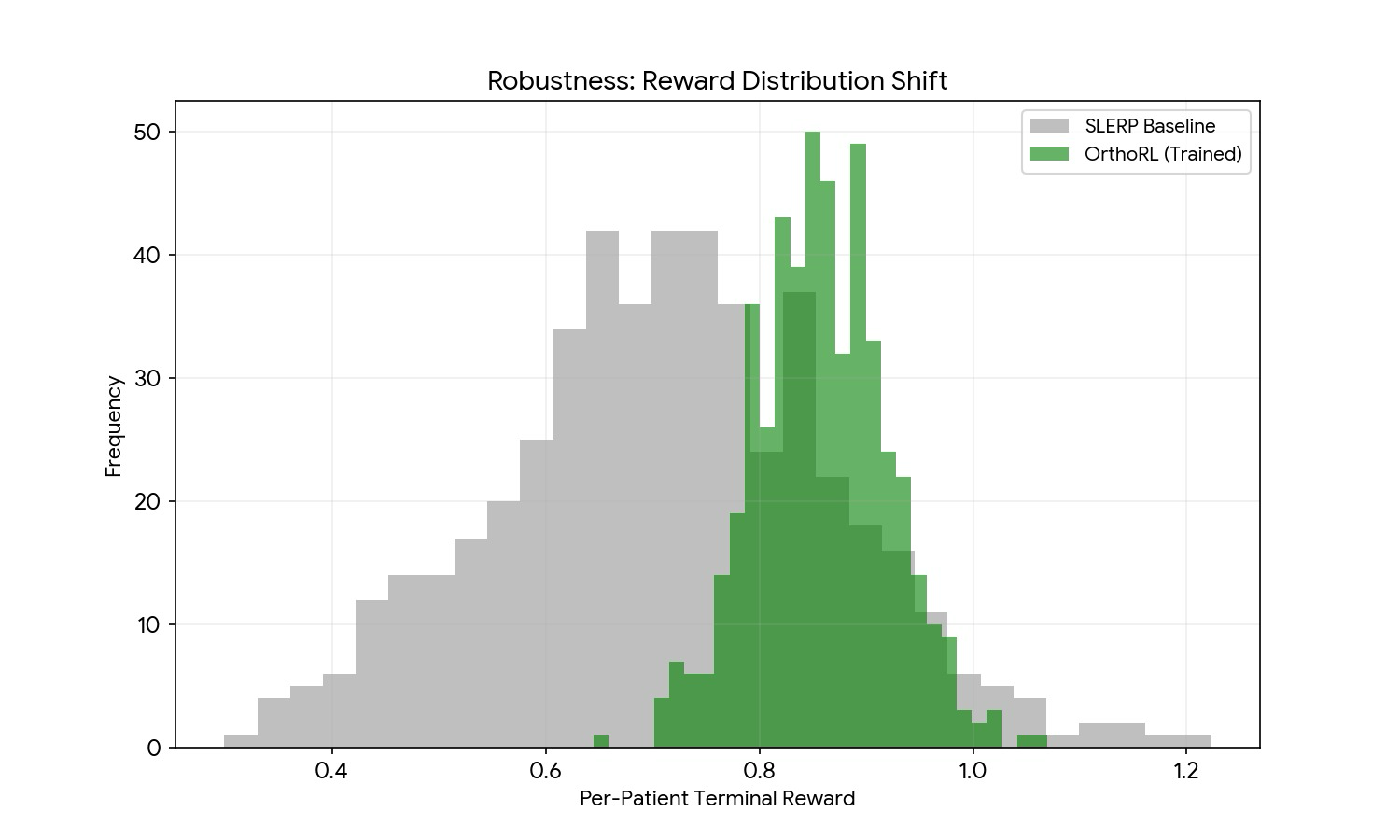
Per-patient reward distribution shift
Overlapping histograms of per-patient terminal reward across the same 250 cases. Grey (SLERP) is broad and centred near 0.7 with a long left tail of failures. Green (OrthoRL) is narrow, centred near 0.86, and the entire left tail (the 30–50% “refinement-trap” cases) is gone. Robustness, not just average performance.
What we considered — and what we built.
Pharmacokinetic force decay
Bone remodels on a 0–8 week impulse response (Proffit Ch. 8).
Our env applies kernel [0.10, 0.30, 0.40, 0.15, 0.05] so SLERP overshoots
and the agent must plan 2 stages ahead.
Empirical anchorage prior
Real molars move only 0.89 mm median across 5,089 tooth-class observations from 195 Tsinghua treated cases. The agent learns this without ever being told — the reward is mined from data, not hand-tuned.
Three-tier held-out eval
Tsinghua test (250) + Open-Full-Jaw (17) + Bits2Bites (40) — frozen IDs,
hard-rejected at /reset in train mode. CI test pinned. No
leakage path exists.
Auditable LLM-judge
Memo claims must match trajectory evidence — 5 claim verifiers
(anchorage · AP-correction · IPR · midline · sequencing) with separated thresholds
(0.20 mm conservative, 0.40 mm aggressive). Surface fluency earns nothing;
an agent claiming "conservative anchorage" needs molars under 0.20 mm/stage.
Adversarial non-compliance
Three stochastic modes — missed_wear, broken_attachment,
partial_wear — injected mid-trajectory. The agent must recover and re-plan,
not optimise a deterministic SLERP path. Most RL envs assume clean dynamics; ours doesn't.
Reward-hacking defense
Five independent reward funcs (format · terminal ·
occlusion · strategy · anchorage) — no single signal can be gamed.
LLM judge gated by claim verifiers, anchorage prior mined from 5,089 obs (not hand-tuned),
test IDs hard-rejected at /reset. Every reward is independently grounded.